OmicScope Overview¶
This section provides an overview of the functionalities of the OmicScope module, including instructions on how to use the OmicScope package to extract biological information.
OmicScope Object¶
After importing data into OmicScope, users can access both the input parameters and the resulting data.
import omicscope as omics
data = omics.OmicScope('../../tests/data/proteins/progenesis.xls', Method = 'Progenesis', ControlGroup = 'CTRL')
OmicScope v 1.4.0 For help: https://omicscope.readthedocs.io/en/latest/ or https://omicscope.ib.unicamp.brIf you use in published research, please cite:
'Reis-de-Oliveira, G., et al (2024). OmicScope unravels systems-level insights from quantitative proteomics data
User already performed statistical analysis
OmicScope identifies: 697 deregulations
OmicScope records all steps in Object.Params, allowing users to document results and save all parameters utilized in the analysis.
import pandas as pd
# user can display using dictionary or pandas dataframe
print(data.Params)
pd.DataFrame(data.Params)
{'Params': {'ImportMethod': 'Progenesis', 'ImportWarning_1': 'Quantification using Normalized Abundance', 'Stats': 'Imported from user data', 'Stats_Warning1': 'Only 1 experimental group identified', 'Stats_Warning_2': 'Drop protein contaminants based on Frankenfield, 2022'}}
| Params | |
|---|---|
| ImportMethod | Progenesis |
| ImportWarning_1 | Quantification using Normalized Abundance |
| Stats | Imported from user data |
| Stats_Warning1 | Only 1 experimental group identified |
| Stats_Warning_2 | Drop protein contaminants based on Frankenfiel... |
Conditions¶
Users can access the conditions evaluated during proteomics experiments by using the following code:
data.Conditions
['CTRL', 'COVID']
In the example above, two groups (“CTRL” and “COVID”) were identified as conditions.
By default, OmicScope sorts conditions in alphabetical order and selects
the first one to be considered the “Control Group,” which is crucial for
some plots (such as the volcano plot). However, in the data analyzed
here, we defined ControlGroup as ‘CTRL’ to fit scientific purposes.
The ControlGroup, whether user-defined or OmicScope-defined, can be
accessed through object.ControlGroup (see below).
data.ControlGroup
'CTRL'
Differential Expression Analysis¶
Differential expression analysis in OmicScope generates results stored
in the quant_data object. This tabular data combines results from
the assay (object.expression), pdata (object.pdata), and rdata
(object.rdata).
Consequently, quant_data includes information about quantified
proteins, such as identification results, gene names, p-values, adjusted
p-values, abundance in each sample, mean abundance in each group, and
fold-change.
data.quant_data.head()
| Accession | Peptide count | Unique peptides | Confidence score | pvalue | pAdjusted | Max fold change | Power | Highest mean condition | Lowest mean condition | ... | VCC_HB_F_1.CTRL | VCC_HB_F_1_2.CTRL | VCC_HB_G_1.CTRL | VCC_HB_G_1_2.CTRL | TotalMean | mean CTRL | mean COVID | fc | log2(fc) | -log10(pAdjusted) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | P0DJI8 | 1 | 1 | 6.8809 | 0.000000e+00 | 0.000000 | 2.192654 | 1.000000 | COVID | CTRL | ... | 12731.691404 | 13233.853968 | 15059.764993 | 12423.510364 | 2.387711e+04 | 13618.731398 | 2.986117e+04 | 2.192654 | 1.132678 | inf |
| 2 | P03886 | 3 | 0 | 24.0213 | 1.299387e-07 | 0.000041 | 1.386199 | 0.999998 | CTRL | COVID | ... | 122412.705135 | 115490.657307 | 136493.069796 | 143254.473213 | 9.672463e+04 | 117378.518567 | 8.467654e+04 | 0.721397 | -0.471134 | 4.390512 |
| 3 | Q9BSM1 | 2 | 2 | 12.2670 | 5.516988e-07 | 0.000105 | 1.726615 | 0.999984 | COVID | CTRL | ... | 16792.299671 | 17921.537559 | 21259.563932 | 23265.526938 | 3.388698e+04 | 23227.525099 | 4.010499e+04 | 1.726615 | 0.787946 | 3.979791 |
| 4 | O94819 | 32 | 16 | 190.5708 | 5.575815e-07 | 0.000105 | 1.245223 | 0.999984 | COVID | CTRL | ... | 770950.278605 | 798518.655465 | 847853.002726 | 836297.424534 | 1.025731e+06 | 888172.927691 | 1.105973e+06 | 1.245223 | 0.316404 | 3.979791 |
| 5 | Q14894 | 17 | 8 | 146.9671 | 7.825126e-07 | 0.000111 | 1.451950 | 0.999974 | COVID | CTRL | ... | 477789.148751 | 479162.075245 | 557800.495276 | 576637.794756 | 6.018212e+05 | 468182.298998 | 6.797772e+05 | 1.451950 | 0.537992 | 3.953746 |
5 rows × 56 columns
The code below demonstrates all the information available in
quant_data for this specific dataset.
Please note that each import method (See Input page) incorporates specific features associated with the outputs from the respective identification and quantitation software.
data.quant_data.columns
Index(['Accession', 'Peptide count', 'Unique peptides', 'Confidence score',
'pvalue', 'pAdjusted', 'Max fold change', 'Power',
'Highest mean condition', 'Lowest mean condition', 'Description',
'gene_name', 'VCC_HB_1_1_2020.COVID', 'VCC_HB_1_2.COVID',
'VCC_HB_2_1.COVID', 'VCC_HB_2_1_2.COVID', 'VCC_HB_3_1.COVID',
'VCC_HB_3_1_2.COVID', 'VCC_HB_4_1.COVID', 'VCC_HB_4_1_2.COVID',
'VCC_HB_5_1.COVID', 'VCC_HB_5_1_2.COVID', 'VCC_HB_6_1.COVID',
'VCC_HB_6_1_2.COVID', 'VCC_HB_7_1.COVID', 'VCC_HB_7_1_2.COVID',
'VCC_HB_8_1.COVID', 'VCC_HB_8_1_2.COVID', 'VCC_HB_9_1.COVID',
'VCC_HB_9_1_2.COVID', 'VCC_HB_10_1.COVID', 'VCC_HB_10_1_2_.COVID',
'VCC_HB_11_1.COVID', 'VCC_HB_11_1_2_.COVID', 'VCC_HB_12_1.COVID',
'VCC_HB_12_1_2_.COVID', 'VCC_HB_A_1.CTRL', 'VCC_HB_A_1_2.CTRL',
'VCC_HB_B_1.CTRL', 'VCC_HB_B_1_2.CTRL', 'VCC_HB_C_1.CTRL',
'VCC_HB_C_1_2.CTRL', 'VCC_HB_D_1.CTRL', 'VCC_HB_D_1_2.CTRL',
'VCC_HB_E_1.CTRL', 'VCC_HB_E_1_2.CTRL', 'VCC_HB_F_1.CTRL',
'VCC_HB_F_1_2.CTRL', 'VCC_HB_G_1.CTRL', 'VCC_HB_G_1_2.CTRL',
'TotalMean', 'mean CTRL', 'mean COVID', 'fc', 'log2(fc)',
'-log10(pAdjusted)'],
dtype='object', name=0)
A more concise dataset, containing only differentially regulated
proteins, can be found in object.deps.
data.deps
| gene_name | Accession | pAdjusted | -log10(pAdjusted) | log2(fc) | |
|---|---|---|---|---|---|
| 0 | SAA1 | P0DJI8 | 0.000000 | inf | 1.132678 |
| 2 | MT-ND1 | P03886 | 0.000041 | 4.390512 | -0.471134 |
| 3 | PCGF1 | Q9BSM1 | 0.000105 | 3.979791 | 0.787946 |
| 4 | KBTBD11 | O94819 | 0.000105 | 3.979791 | 0.316404 |
| 5 | CRYM | Q14894 | 0.000111 | 3.953746 | 0.537992 |
| ... | ... | ... | ... | ... | ... |
| 730 | NDUFAF4 | Q9P032 | 0.049305 | 1.307110 | -0.309369 |
| 731 | HPCAL1 | P37235 | 0.049335 | 1.306847 | 0.273795 |
| 732 | METTL7A | Q9H8H3 | 0.049393 | 1.306333 | 0.432424 |
| 733 | NDEL1 | Q9GZM8 | 0.049710 | 1.303558 | 0.191609 |
| 734 | TKFC | Q3LXA3 | 0.049777 | 1.302972 | 0.248767 |
697 rows × 5 columns
Plots and Figures¶
Plots and figures play crucial roles in the OmicScope workflow, aiding in data visualization and providing insights into proteomics datasets. The OmicScope figures toolset empowers researchers to assess data normalization, explore specific proteins, conduct clustering analysis, examine time course experiments, and investigate protein-protein interactions.
All plot functions offer numerous visualization parameters, enabling users to customize plots and generate figures ready for publication. Additionally, several functions allow users to highlight or select proteins of interest for plotting. To do so, simply specify the protein’s gene name at the beginning of the function call. Furthermore, OmicScope provides color palette options based on the recommendations of the Matplotlib package.
Moreover, for plots requiring data processing (such as heatmaps, PCA, etc.), users can adjust certain metrics to obtain better results.
Finally, all figures generated by OmicScope can be saved using the
save parameter (save = "PATH_OF_FOLDER_TO_SAVE"), either as
vector graphics (with the .svg extension, using vector=True) or
as static images (with the .png extension, using vector=False).
By default, the resolution is set to 300 dpi (dpi=300).
Please refer below for each plot generated by OmicScope.
General Figures¶
Identification Barplot - object.bar_ident()¶
The bar_ident() function generates a bar plot displaying the number
of quantified proteins and differentially regulated proteins in the
experiment. It can perform a log-transformation of the y-axis for better
visualization.
How to Interpret: This plot provides an initial overview of the data, allowing you to evaluate the proportion of differentially regulated proteins in relation to the whole proteome analyzed.
data.bar_ident(logscale=True, dpi = 90)
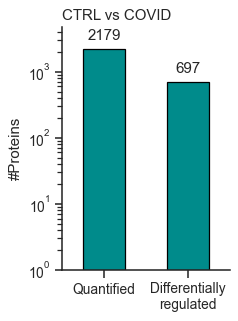
<AxesSubplot: title={'left': 'CTRL vs COVID'}, ylabel='#Proteins'>
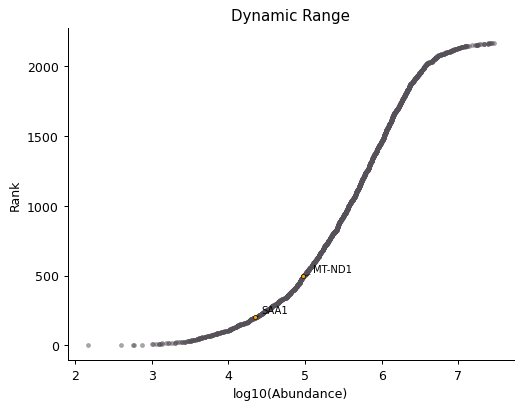
Dynamic Range Plot - object.DynamicRange()¶
The Dynamic Range plot is a classic in proteomics studies. It ranks proteins by abundance on a log-scale (x-axis) and plots them along the y-axis.
In the function below, it is possible to annotate proteins of interest
in the plot by adding their gene_name as args.
How to Interpret: This plot can highlight proteome coverage and suggest proteins with low abundance (bottom-left side of the plot) or high abundance (top-right side of the plot).
This plot helps users investigate experimental issues and determine if proteins of interest are present in low or high abundance. In proteomics, low abundance is often associated with missing values, greater variation in abundance, and challenges in performing statistical analyses.
data.DynamicRange('SAA1', 'MT-ND1',dpi = 90)
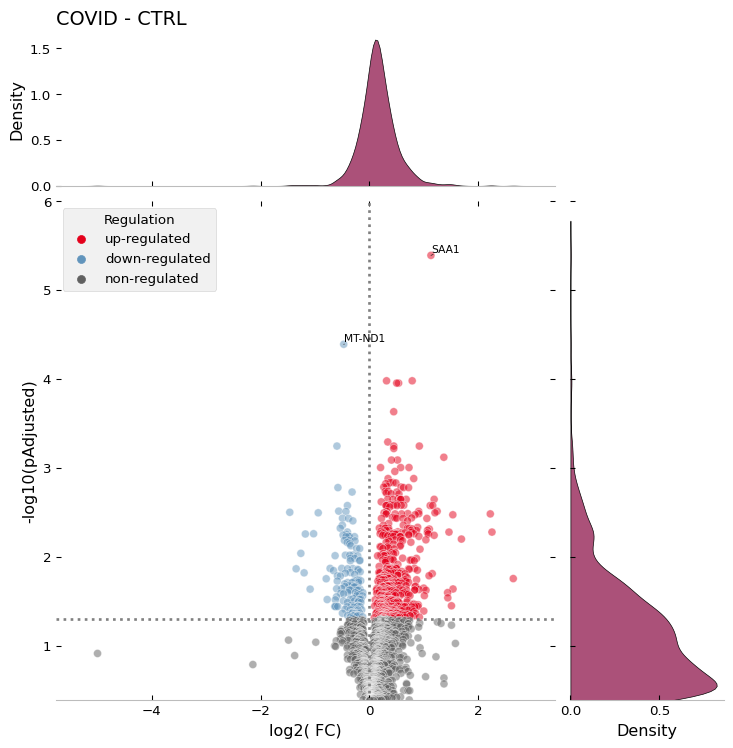
Volcano Plot - object.volcano()¶
The volcano plot is another scatter plot commonly used in proteomics experiments. In this plot, each protein is represented with log-transformed statistical values (e.g., p-value or adjusted p-value) on the y-axis and log2-transformed fold change on the x-axis.
When evaluating two groups, OmicScope generates a conventional volcano plot, displaying positive (up-regulated) and negative (down-regulated) proteins on the x-axis. For comparisons involving more groups, OmicScope shows only positive fold changes, labeling different groups and comparisons performed.
How to Interpret: This plot allows users to assess the magnitude and statistical significance of the differences between groups at proteome level. The farther a protein is from the origin of the plot, the greater the significance of its difference between groups. In addition to highlighting differentially regulated proteins, the plot serves as a proxy for quality control of normalization methods, as the data should exhibit a normal distribution on the x-axis and a positively skewed distribution on the y-axis.
data.volcano('SAA1', 'MT-ND1',dpi = 96)
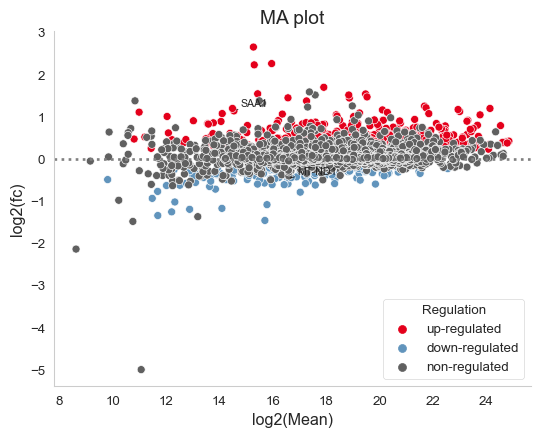
MA Plot - object.MAplot()¶
The Moving-Average plot (MA plot) is a scatter plot that assigns each protein its log-transformed abundance (y-axis) and log-transformed fold change (x-axis). In OmicScope, differentially regulated proteins are color-coded accordingly. This plot combines the information from both the volcano plot and the dynamic range plot, providing an alternative visualization strategy.
How to Interpret: This plot helps users evaluate data normalization. It is generally expected that only a few proteins (colored) will exhibit significant changes in expression. High deviations from zero on the y-axis may indicate that the data requires an alternative normalization method.
data.MAplot('SAA1', 'MT-ND1', dpi=96)
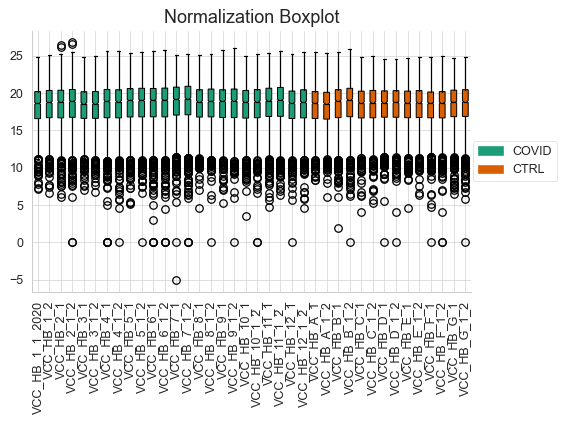
Normalization Boxplot - object.normalization_boxplot()¶
Normalizing data is a pivotal step in differential proteomics experiments. Therefore, OmicScope also generates boxplots of protein abundance distribution (y-axis) across samples (x-axis).
How to Interpret: This plot helps users assess data normalization performed prior differential proteomics analysis. It is expected that samples will present similar mean abundances and error ranges. If this does not occur, users should consider trying alternative normalization methods and/or excluding potential sample outliers before performing differential proteomics analysis again.
data.normalization_boxplot(dpi=90)
Evaluate Abundance of a Subset of Proteins¶
OmicScope offers two options for visualizing individual proteins: barplots and boxplots. Both functions work similarly, allowing users to specify target proteins and plot their abundances (y-axis) across groups (x-axis). The result is a single figure encompassing all selected proteins and their respective conditions, with the option of performing log-transformation of protein abundance.
How to Interpret: Barplots and boxplots are used to compare protein abundance across groups, enabling users to evaluate mean abundance along with respective errors and data distribution. These plots are particularly useful for searching specific targets in an attempt to validate findings or conduct in-depth investigations.
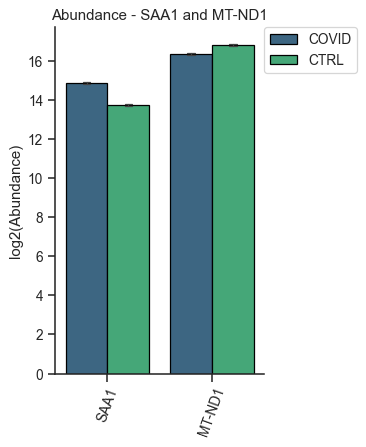
Bar plot of proteins - object.bar_protein(args)¶
In the protein bar plot, OmicScope considers the mean as the estimator and adds error bars representing the standard error.
data.bar_protein('SAA1', 'MT-ND1', logscale=True, palette='viridis', dpi=90)
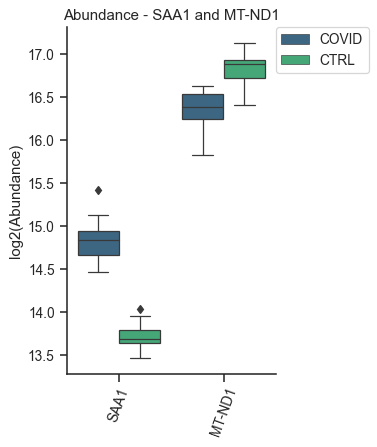
Boxplot plot of proteins - object.bar_protein(args)¶
The boxplot displays the median, quartiles, and potential outliers of the protein abundance among conditions. The box represents the quartiles of the dataset, while the whiskers extend to show the rest of the distribution, excluding points that are identified as “outliers”.
data.boxplot_protein('SAA1', 'MT-ND1', palette='viridis', dpi=90)
Clustering Analysis¶
As with all Omics technologies, proteomics experiments generate large amounts of data. Organizing this data and extracting biological information can be challenging tasks. Therefore, clustering algorithms are often applied to organize information, verify sample clustering, evaluate co-expression patterns, and identify patterns among differentially regulated proteins.
To address this diversity of analyses, OmicScope provides four plots that utilize distinct clustering algorithms: hierarchical clustering, principal component analysis (PCA), and k-means.
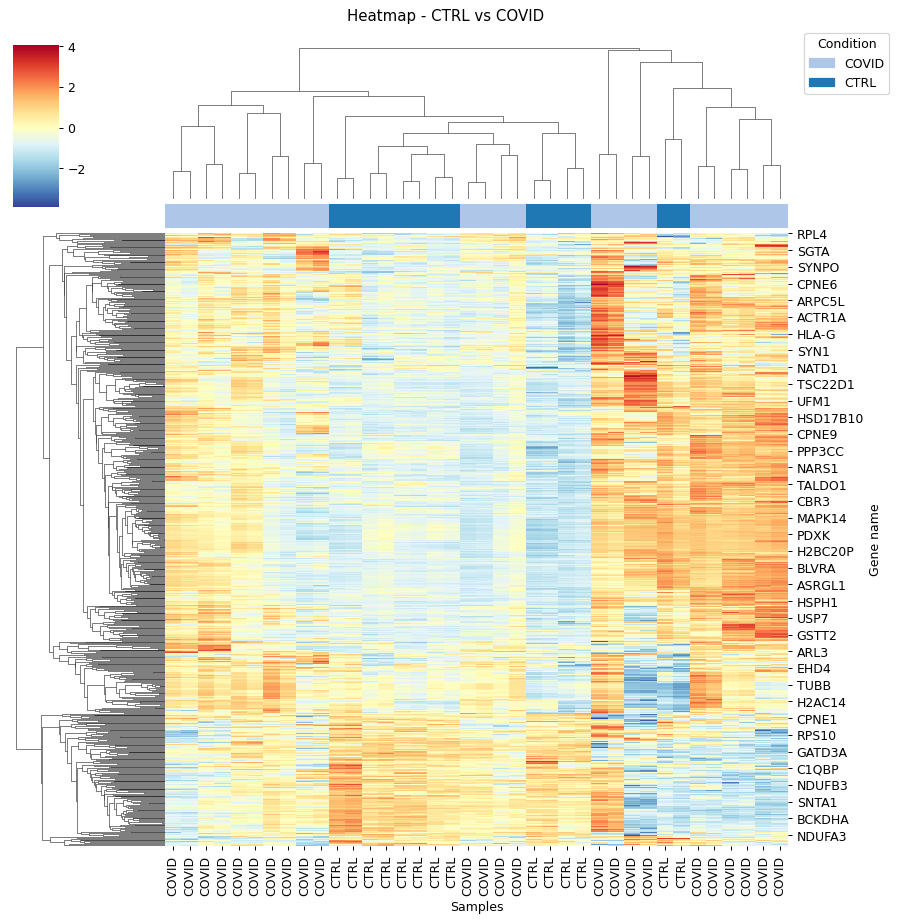
Heatmap - object.heatmap()¶
The heatmap function utilizes protein (y-axis) and sample (x-axis) information to perform hierarchical clustering. Users can optionally specify alternative metrics for calculating distances between clusters or methods for performing cluster linkage. For more information about these parameters and all available options, please refer to the documentation for metric distance and clustering linkage.
Other arguments of the Heatmap function are for visualization purposes. Additionally, this function allows users to select specific proteins to generate the heatmap from a subset of target proteins.
How to Interpret: The heatmap helps users identify clusters of proteins that can distinguish between groups, as well as the patterns associated with each condition. In longitudinal experimental designs, OmicScope also labels the time points for convenient analysis. When performing longitudinal experimental designs, it is common practice not to perform column clustering to allow visualization of the protein abundance changing over time among conditions.
data.heatmap(dpi=90, linewidth=0)
Sample Correlation - object.correlation()¶
This function calculates pair-wise correlations between samples using Pearson’s correlation algorithm by default. OmicScope then performs hierarchical clustering on the correlation matrix. Besides the metrics and linkage methods found in the heatmap function, this function also allows users to use other correlation indices such as ‘kendall’ or ‘spearman’ to perform pair-wise correlation.
To evaluate similarity considering the whole proteome, the correlation function sets the protein p-value as 1.0 by default.
How to Interpret: Since this plot evaluates pair-wise similarity between samples, it can be used to identify outliers, technical variations, reproducibility issues, normalization problems, and the impact of differentially regulated proteins on the entire proteome.
data.correlation(dpi=90, linewidth=0)

Principal Component Analysis - object.pca()¶
In proteomics, Principal Component Analysis (PCA) is a dimensionality reduction technique used to cluster samples based on their protein abundance profiles. This analysis transforms high-dimensional proteomics data into a lower-dimensional space by identifying principal components (PCs), which are variables that capture the most variance in the data. The Scree plot presents the variance explained for each PC (left panel), while the clustering analysis is shown in the right panel for the two PCs that explain the most variance (PC1 and PC2).
Notably, OmicScope’s PCA function allows users to adjust the p-value threshold for protein inclusion, which is set to 0.05 by default.
How to Interpret: PCA helps in grouping similar samples. It is expected that samples from the same biological conditions should be closest together, while samples from distinct conditions should be further apart.
data.pca(pvalue = 0.05, dpi = 90)

K-Means - object.k_trend()¶
K-means is a clustering algorithm that partitions data into k clusters. It works by initializing k centroids randomly, then iteratively assigning each data point to the nearest centroid and updating the centroids to be the mean of the assigned points. This process repeats until the centroids no longer change significantly, resulting in clusters where data points within each cluster are more similar to each other than to those in other clusters.
Users can provide the k value to define clusters, such as
k_cluster=2 for up- and down-regulated clusters. However, by
default, OmicScope calculates the optimal k value using a kneed
algorithm.
Longitudinal Purposes: During longitudinal analysis, protein levels may exhibit various patterns over time. For instance, a protein’s abundance might increase in the control group and then decrease, while in the treatment group, the same protein might initially decrease and then increase. To identify these patterns, OmicScope performs k-means clustering to identify protein clusters and then plots the mean protein abundance according to conditions to evaluate how each cluster behaves in each group.
How to Interpret: OmicScope displays all k clusters and the respective mean protein abundance for each sample, split according to group. This plot allows users to identify molecular trends and may suggest proteins that exhibit co-expression patterns. Additionally, OmicScope prints and stores the proteins belonging to each cluster, allowing further investigations on specific subset of proteins.
data.k_trend(dpi=96)
KneeLocator identifies: 4 clusters

| cluster | gene_name | |
|---|---|---|
| 0 | 0 | {SPTBN4, TUBB4A, CMPK1, GNG4, RAP1A, DHODH, HA... |
| 1 | 1 | {HLA-H, GNAZ, ATP4A, RPL27A, SEPTIN14, CHCHD3,... |
| 2 | 2 | {IZUMO1, MGST3, MT-ND6, MT-CO1, LIN28A, NDUFAF... |
| 3 | 3 | {FTCD, ESYT1, TIPRL, LDHA, TRAP1, FLOT1, BLVRA... |
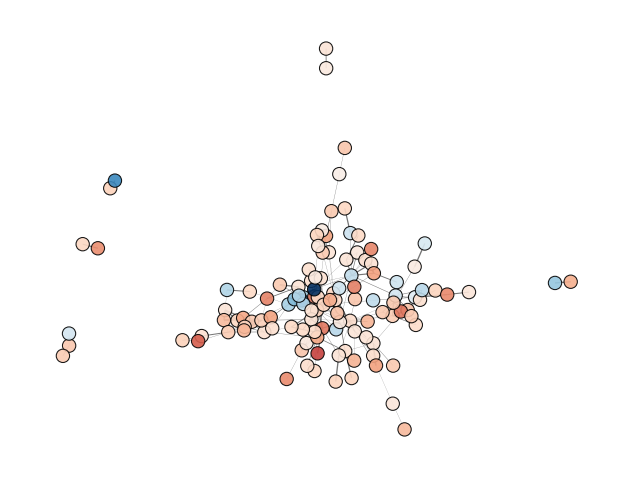
Protein-Protein Interactions - object.PPInteractions()¶
Proteomics data analysis solely based on protein abundance can be challenging when trying to derive biological insights. To overcome this limitation, OmicScope utilizes the STRING API to retrieve protein-protein interactions, including functional or physical interactions.
The PPInteractions function in OmicScope allows users to customize
the evidence score for considering protein-protein interactions (default
set to 0.7). It also supports searching for communities based on the
Louvain algorithm and choosing between physical or functional
interactions (default set to 'functional'). Users need to specify
the correct NCBI identifier for the organism under study (default set to
9606 for Human; other options include Mus musculus = 10090, and
Rattus norvegicus = 10116).
Since the complexity of plotting graphs can vary depending on the data,
OmicScope provides the option to export network data to visualization
software like Cytoscape and Gephi for more comprehensive and customized
visualization. To export a plot to other tools, users only need to
specify the save parameter as the path to save the file.
How to Interpret: Each node represents a protein, while edges represent PPIs that passed the score threshold. The colors of the nodes indicate protein fold changes, while the edge widths indicate the PPI score. When performing the Louvain clustering algorithm, the node edge color is also related to a specific module.
data.PPInteractions(pvalue=0.01, dpi=96)
<networkx.classes.graph.Graph at 0x1d046804650>